Introduction
One of the common requirements in programming is to implement a hierarchy of entities. Anyone can list several examples from their own experience: the hierarchy of directories, the hierarchy of company branches and departments, the hierarchy of people employed in a company, etc.
The simplest and widely used method to represent such hierarchies is to assign every instance a reference to the parent instance. When this idea comes to the ground of database programming, it becomes a well-known fishhook relation, i.e. a foreign key that references the same table in which it is declared. For example, in the Employee table, with primary key EmployeeID, foreign key SuperiorEmployeeID would reference the EmployeeID column in order to specify the superior person to any given employee. Value NULL would then indicate a rare and joyful case of an employee without anybody positioned above. The name fishhook derives from the visual representation of such foreign keys, as shown in the following picture.
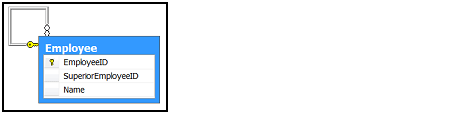
This simple design allows the application to represent a hierarchy of arbitrary size and depth, which is a significant power in many practical applications. Add to this the fact that the application can query child entities very simply, by selecting them by parent identity, and it becomes obvious why this solution is so widely used. But now, we come to the point at which we should ask what are particular operations performed on this structure and how these operations can be implemented.
We will first identify requirements that one system operating on hierarchies should meet. Then complete solution on a simple example will be provided.
Requirements
Broadly speaking, an application that operates on a hierarchy of entities should be able to construct, maintain and report the hierarchy. If hierarchy is viewed as a tree structure, as it is when fishhook relation is used, then required operations can be precisely defined like this:
Insertion
Adding a new item to the tree, specifying the parent item under which the new one will be inserted. Optionally, child nodes in the tree might be ordered and this operation might also require a position within the child list at which a new node should be inserted. In that case, the positions of siblings might need to be updated.
Accessing one item
This operation may be defined in many ways. For example, by searching the tree from the root towards the required item, and similar. It is up to a particular application to define this operation precisely. For example, in a directory tree case, a directory's full path can be broken down into segments, each segment representing the name of one directory in the hierarchy. The application would traverse the tree from the root towards the child, at each level selecting a node based on the corresponding directory name in the path.
Updating one item
Once the item is located, it can be changed. This might as well have an effect on the tree structure. The application must be aware of pitfalls like attempting to move an item under another item that is actually its own descendant. Such an operation would create a loop, which is of course not allowed in the tree structure.
Deleting a node with all its descendants
This is a complex operation that requires an application to identify all descendants of one node before removing them from the tree. It cannot be implemented by using the ON DELETE CASCADE option in the database simply because cascade deletion is not allowed on fishhook relation. Consequently, the application must traverse the subtree rooted at the target node, deleting all nodes visited in a bottom-up manner, i.e. in such a way that any node visited is deleted only after all its descendants have already been deleted.
Reporting the subtree
This is another complex operation that requires an application to traverse the subtree in a depth-first order, printing out all nodes visited, so that the output takes a familiar look like a directory tree in file system browsers.
In the following sections, we will propose a solution that offers all these operations in one simple example.
Proposed Solution
The first issue which must be discussed here is this: What is the natural place at which functionality regarding the table with fishhook relation should be implemented? Generally, there are two candidates: one is the middle tier and another one is the data tier.
In the first case, the database would only provide a crude interface to allow the application to operate on raw data. It is the application's obligation in that case to guarantee data integrity, e.g. that there are no loops in the tree. In the second case, when all logic is located in the database, the application has no concerns about data integrity. It is all maintained by the database itself and the database would provide a high-level interface, exposing only complex and well-defined operations on the tree.
In this article, we will stick to the second solution, and here is why. Working with hierarchies is quite complex as can be seen from the list of required operations. Leaving all these complex operations to the application may be risky because data might become corrupt or inconsistent, without the possibility for the database to control and prevent damage to the data. On the other hand, if one tries to allow the database to control the storage in such a way that integrity is preserved, logic would be spread both in the application and in the database, which is probably the worst possible design. Furthermore, if multiple applications would desire to access the same database, they would all have to implement this same logic. This is likely to become a serious task, especially if different languages are used to program different components.
All these reasons advocate placing the logic into the database. And once that is done, there come the benefits. For example, we can afford some level of modifications of database schema without modifying the applications. Further on, some operations might be implemented using different shortcuts and optimizations that might not be accessible to the application. For example, deleting a complete tree could be very difficult for the application because it would have to traverse the tree and delete nodes one by one. On the contrary, if this operation is implemented in the database, it could benefit from the knowledge of the internal structure of the affected tables and use it for the better. Deletion would then be implemented in two simple steps: in the first step parent reference would be set in all nodes to NULL, virtually dispersing the tree into a cluster of unconnected nodes; only then, the second step comes and that deletes all rows in the table. Since parent references have been removed (replaced with NULL), no error would occur in this bulk delete operation and that would be much faster than deleting the nodes one at a time.
Example Solution
Suppose that we are dealing with a directory system, each directory being part of the parent directory unless it is the root of the file system. Here is the definition of the table with fishhook relation which can contain the directory structure:
CREATE TABLE Directory
(
DirectoryID INT PRIMARY KEY IDENTITY(1, 1),
ParentDirectoryID INT FOREIGN KEY REFERENCES Directory(DirectoryID) ON DELETE NO ACTION,
Name NVARCHAR(1000) NOT NULL,
Ordinal INT NOT NULL, -- One-based ordinal number of the directory
Depth INT NOT NULL -- Zero-based depth of the directory
);
This table contains the name of every directory and a reference to its parent. The full path is constructed by iterating through parents up to the file system root, concatenating all directories visited (in reverse order). Note that every directory has its own position within the parent directory. This could resemble the order of insertions, lexicographical order, or any other order desired by the application. The depth field represents the depth of the directory within the directory structure, with the value zero indicating the root directory.
The basic operation would be to insert a new directory into this table. We can create a procedure that receives the name of the new directory, reference to the parent directory, and optional ordinal number. If the ordinal number is missing (i.e. NULL), a new directory would be added at the end of the list of subdirectories of its parent. To cut the long story short, here is the procedure listing:
CREATE PROCEDURE CreateDirectory
(
@Name NVARCHAR(1000),
@ParentDirectoryID INT,
@Ordinal INT -- if NULL, directory will be inserted as last within parent
)
AS
BEGIN
DECLARE @MaxSiblingOrdinal INT
DECLARE @Depth INT = 0
SELECT @MaxSiblingOrdinal = MAX(Ordinal) FROM Directory
WHERE (ParentDirectoryID = @ParentDirectoryID OR (ParentDirectoryID IS NULL AND @ParentDirectoryID IS NULL))
IF @ParentDirectoryID IS NOT NULL SELECT @Depth = Depth + 1 FROM Directory WHERE DirectoryID = @ParentDirectoryID
IF @MaxSiblingOrdinal IS NULL SET @MaxSiblingOrdinal = 0 -- New directory is the first child of its parent
IF @Ordinal IS NULL OR @Ordinal > @MaxSiblingOrdinal + 1 SET @Ordinal = @MaxSiblingOrdinal + 1 -- @Ordinal was too large; must be set to max+1
-- Now suppose that @Ordinal comes into the middle - ordinal positions of other siblings must be increased by one
UPDATE Directory SET Ordinal = Ordinal + 1
WHERE (ParentDirectoryID = @ParentDirectoryID OR (ParentDirectoryID IS NULL AND @ParentDirectoryID IS NULL)) AND Ordinal >= @Ordinal
INSERT INTO Directory(Name, ParentDirectoryID, Ordinal, Depth) VALUES (@Name, @ParentDirectoryID, @Ordinal, @Depth)
RETURN @@IDENTITY
END
GO
The procedure first tries to determine the actual ordinal position of the new directory. If the input parameter is null or larger than the existing maximum ordinal value, then it is set so that the new directory gets the ordinal value by one larger than any other sibling, effectively being pushed to the end of the list of its siblings.
Once an ordinal position is determined, other directories within the same parent might require an update on their own ordinal positions so that the new directory perfectly fits within the uninterrupted sequence of ordinal positions. Finally, a new directory is created by inserting a row into the table.
This procedure is a powerful tool to insert new directories into the tree, but it lacks simplicity – its interface is based on knowing the identity of the parent directory. Wouldn't it be better to use backslash-delimited paths instead of directory identities? We can try that approach by defining a procedure that only receives a path to the directory which should be created:
CREATE PROCEDURE CreatePath
(
@Path NVARCHAR(1000)
)
AS
BEGIN
DECLARE @ParentDirectoryID INT = NULL
DECLARE @Name NVARCHAR(1000)
DECLARE @DelimiterIndex INT
DECLARE @Ordinal INT
DECLARE @DirectoryID INT
WHILE LEN(@Path) > 0
BEGIN
SET @DelimiterIndex = CHARINDEX('\', @Path)
IF @DelimiterIndex > 0
BEGIN
SET @Name = SUBSTRING(@Path, 1, @DelimiterIndex - 1)
SET @Path = SUBSTRING(@Path, @DelimiterIndex + 1, LEN(@Path) - @DelimiterIndex)
END
ELSE
BEGIN
SET @Name = @Path
SET @Path = ''
END
-- Now check whether the directory already exists
SET @DirectoryID = NULL
SELECT @DirectoryID = DirectoryID FROM Directory
WHERE (ParentDirectoryID = @ParentDirectoryID OR (ParentDirectoryID IS NULL AND @ParentDirectoryID IS NULL)) AND Name = @Name
IF @DirectoryID IS NULL
BEGIN -- Directory does not exist and must be created
-- Now calculate ordinal position so that new directory takes position of the first directory with lexicographically larger name
SET @Ordinal = NULL
SELECT @Ordinal = MIN(Ordinal) FROM Directory
WHERE (ParentDirectoryID = @ParentDirectoryID OR (ParentDirectoryID IS NULL AND @ParentDirectoryID IS NULL)) AND Name >= @Name
EXEC @ParentDirectoryID = CreateDirectory @Name, @ParentDirectoryID, @Ordinal
END
ELSE
SET @ParentDirectoryID = @DirectoryID
END
END
GO
This procedure breaks down the path into segments, each segment representing one directory, and then creates all directories that are missing, including the last one which corresponds with the full path. The approach demonstrated by this procedure is favorable in practice because the application is completely relieved from thinking about the directory structure – it rather operates on directory paths and lets the database keep the record. Here is a demonstration of how simple it is to use such a procedure.
- EXEC CreatePath 'C:\Temp'
- EXEC CreatePath 'C:\Windows\System'
- EXEC CreatePath 'C:\Pictures'
- EXEC CreatePath 'C:\Program Files\Windows Media Player'
- EXEC CreatePath 'C:\Windows\System32\WindowsPowerShell'
- EXEC CreatePath 'C:\Windows\System32\wbem'
- EXEC CreatePath 'C:\Windows\System32\spool'
This set of calls will actually create 11 directories, as can be seen, if content of the Directory table is listed:
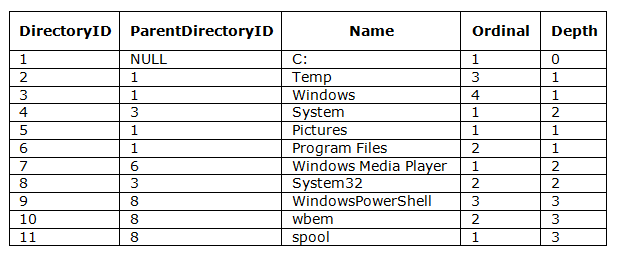
All directories along the paths have been created, and all ordinal positions and depths maintained as new directories were added to the tree. Application was only supposed to perform trivial calls just passing the desired full directory path.
We can go even further and define a utility procedure that converts the full directory path into the corresponding directory identity (without creating the directory):
CREATE PROCEDURE GetDirectoryID
(
@Path NVARCHAR(1000)
)
AS
BEGIN
DECLARE @DirectoryID INT = NULL
DECLARE @ChildDirectoryID INT
DECLARE @Name NVARCHAR(1000)
DECLARE @DelimiterIndex INT
WHILE LEN(@Path) > 0
BEGIN
SET @DelimiterIndex = CHARINDEX('\', @Path)
IF @DelimiterIndex > 0
BEGIN
SET @Name = SUBSTRING(@Path, 1, @DelimiterIndex - 1)
SET @Path = SUBSTRING(@Path, @DelimiterIndex + 1, LEN(@Path) - @DelimiterIndex)
END
ELSE
BEGIN
SET @Name = @Path
SET @Path = ''
END
-- Now check whether the directory already exists
SET @ChildDirectoryID = NULL
SELECT @ChildDirectoryID = DirectoryID FROM Directory
WHERE (ParentDirectoryID = @DirectoryID OR (ParentDirectoryID IS NULL AND @DirectoryID IS NULL)) AND Name = @Name
IF @ChildDirectoryID IS NULL
BEGIN
SET @Path = '' -- This will cause loop to exit and procedure to fail by returning negative value
SET @DirectoryID = NULL
END
ELSE
SET @DirectoryID = @ChildDirectoryID
END
IF @DirectoryID IS NULL SET @DirectoryID = -1
RETURN @DirectoryID
END
GO
Procedure GetDirectoryID operates similarly to CreatePath procedure, by splitting the path into segments and walking along the hierarchy of directories until the last child is found which corresponds with the full path. GetDirectoryID procedure may fail, if required directory does not exist, and then it would simply return negative value instead of regular directory identity. This procedure is then used as a utility to convert paths into identities, so that application may never need to remember directory identity as long as it remembers paths, which are meaningful to the user and more readable.
Now comes the real piece of work, and that is the procedure which deletes the subtree.
CREATE PROCEDURE DeleteDirectoryRecursive
(
@Path NVARCHAR(1000)
)
AS
BEGIN
DECLARE @stack TABLE(Position INT, DirectoryID INT) -- Table emulating stack used to traverse child documents depth-first
DECLARE @stackPos INT = 0 -- Number of elements on stack; zero indicates that stack is empty
DECLARE @curDirectoryID INT -- Identity of the directory which is currently on top of the stack
DECLARE @curChildDirectoryID INT -- Identity of the child document which is currently being pushed to the stack
DECLARE @parentDirectoryID INT -- Identity of the parent document of @DocumentID
DECLARE @ordinal INT -- Ordinal number of the deleted directory, used to update ordinal numbers of siblings after directory is deleted
DECLARE @directoryID INT
EXEC @directoryID = GetDirectoryID @Path
IF @directoryID > 0
BEGIN
SET @stackPos = @stackPos + 1
INSERT INTO @stack(Position, DirectoryID) VALUES (@stackPos, @directoryID)
SELECT @parentDirectoryID = ParentDirectoryID, @ordinal = Ordinal FROM Directory WHERE DirectoryID = @directoryID
END
WHILE (@stackPos > 0)
BEGIN -- Repeat while stack is not empty
SELECT @curDirectoryID = DirectoryID FROM @stack WHERE Position = @stackPos
IF EXISTS (SELECT * FROM Directory WHERE ParentDirectoryID = @curDirectoryID)
BEGIN
DECLARE ChildrenCursor CURSOR FOR
SELECT DirectoryID FROM Directory WHERE ParentDirectoryID = @curDirectoryID
OPEN ChildrenCursor
FETCH NEXT FROM ChildrenCursor INTO @curChildDirectoryID
WHILE @@FETCH_STATUS = 0
BEGIN -- Iterate through all child directories and push them to stack
-- Now push new descendant DirectoryID to the stack
SET @stackPos = @stackPos + 1
INSERT INTO @stack(Position, DirectoryID) VALUES (@stackPos, @curChildDirectoryID)
FETCH NEXT FROM ChildrenCursor INTO @curChildDirectoryID
END
CLOSE ChildrenCursor
DEALLOCATE ChildrenCursor
END
ELSE
BEGIN
-- Directory on top of the stack does not contain children, so it can be deleted
DELETE FROM Directory WHERE DirectoryID = @curDirectoryID
DELETE FROM @stack WHERE Position = @stackPos
SET @stackPos = @stackPos - 1
END
END
IF @directoryID IS NOT NULL
BEGIN -- This indicates that directory has been deleted, and now ordinal positions of its siblings must be updated
UPDATE Directory SET Ordinal = Ordinal - 1
WHERE (ParentDirectoryID= @parentDirectoryID OR (ParentDirectoryID IS NULL AND @parentDirectoryID IS NULL)) AND Ordinal > @ordinal
END
END
GO
Please pay attention to this procedure, as it demonstrates the core functionality of the database when working with fishhook relation. We have created a table variable which serves as the stack. Then tree nodes are iterated depth-first using this stack. Whenever a directory is reached which contains children, its children are pushed to the stack. Only when directory on top of the stack has no children can it be popped and deleted from the table. This order of steps guarantees that only rows without referencing descendants will be deleted from the Directory table, which is the required condition for deletion to be successful – otherwise we would only get the error from the database.
With similar ideas behind the code we can create one interesting function:
CREATE FUNCTION GetDirectoryGlobalOrdinalRecursive
(
@RootDirectoryID INT
)
RETURNS @retval Table(DirectoryID INT, GlobalOrdinal INT)
AS
BEGIN
DECLARE @stack TABLE(Position INT, DirectoryID INT) -- Stack used to iterate the documents subtree depth first
DECLARE @stackPos INT = 0 -- Total number of items on stack; NULL indicates that stack is empty
DECLARE @curDirectoryID INT -- Identity of the directory which is currently being pushed to the output
DECLARE @curGlboalOrdinal INT = 0 -- Value of GlobalOrdinal which was assigned to last directory visited
DECLARE @curChildDirectoryID INT -- Identity of the child directory which is currently being visited
IF @RootDirectoryID IS NULL OR EXISTS (SELECT * FROM Directory WHERE DirectoryID = @RootDirectoryID)
BEGIN
SET @stackPos = @stackPos + 1
INSERT INTO @stack(Position, DirectoryID) VALUES (@stackPos, @RootDirectoryID)
WHILE @stackPos > 0
BEGIN
-- Pop directory from stack
SELECT @curDirectoryID = DirectoryID FROM @stack WHERE Position = @stackPos
SET @stackPos = @stackPos - 1
IF @curDirectoryID IS NOT NULL
BEGIN -- @curDirectoryID may be null if all directories are listed
SET @curGlboalOrdinal = @curGlboalOrdinal + 1
INSERT INTO @retval (DirectoryID, GlobalOrdinal) VALUES (@curDirectoryID, @curGlboalOrdinal)
END
DECLARE ChildrenCursor CURSOR FOR
SELECT DirectoryID
FROM Directory
WHERE ParentDirectoryID = @curDirectoryID OR (ParentDirectoryID IS NULL AND @curDirectoryID IS NULL)
ORDER BY Ordinal DESC
OPEN ChildrenCursor
FETCH NEXT FROM ChildrenCursor INTO @curChildDirectoryID
WHILE @@FETCH_STATUS = 0
BEGIN -- Push all child directories to stack
SET @stackPos = @stackPos + 1
INSERT INTO @stack (Position, DirectoryID) VALUES (@stackPos, @curChildDirectoryID)
FETCH NEXT FROM ChildrenCursor INTO @curChildDirectoryID
END
CLOSE ChildrenCursor
DEALLOCATE ChildrenCursor
END
END
RETURN
END
GO
This function starts from the directory and then produces a table containing the identities of that directory and all its descendants, plus one more column giving the global order of directories listed. This function actually sorts the subtree into a list of directories. The result might become clear when the function is used. We will first define a view that uses it:
CREATE VIEW DirectoryOrderV AS
SELECT Directory.*, G.GlobalOrdinal FROM
Directory INNER JOIN
GetDirectoryGlobalOrdinalRecursive(NULL) AS G ON Directory.DirectoryID = G.DirectoryID
This view simply adds directory fields to the function's output. Columns returned by the view are actually all columns from the Directory table plus one column indicating global order among directories. Even without adding a column, it is a good idea to define a view that simply calls the function. This is important because all applications can read from the view, but not every application is equipped to invoke table-returning functions. We can use this view to query the Directory table now:
SELECT * FROM DirectoryOrderV ORDER BY GlobalOrdinal
The output of this query
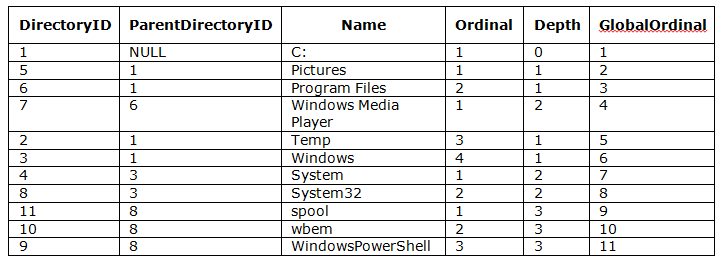
This query shows all the power of keeping logic in the database. With only a single SQL statement application can get hold of the globally sorted directory tree, a result set that it could obtain only with the price of some programming. With help of such views and procedures, applications can become very simple, yet fast and rich in features.
Conclusion
We have shown that database can contain all logic regarding any hierarchy without too much effort. The solution obtained in that way is portable in terms of application, i.e. application can be rewritten in other languages without multiplying the functionality in each implementation and without requiring database changes.
For example, only a couple of lines of C# code are required to print out the complete directory structure to the console.
SqlCommand cmd = new SqlCommand("SELECT Name, Depth FROM DirectoryOrderV ORDER BY GlobalOrdinal", conn);
using (SqlDataReader reader = cmd.ExecuteReader())
{
while (reader.Read())
Console.WriteLine("{0}{1}", new string(' ', 2 * (int)reader["Depth"]), (string)reader["Name"]);
}
This piece of code produces the nicely indented output.
C:
Pictures
Program Files
Windows Media Player
Temp
Windows
System
System32
spool
wbem
WindowsPowerShell
Without all logic already implemented in the database, the application would spread over dozens of lines and, even worse, it might need to communicate with the database many times to list the complete subtree, which is inefficient compared to stored procedures and functions which are executed in one call.
It would require quite a similar programming effort to fill the ASP.NET SiteMap control or Windows Forms TreeView control. With logic left to the application, all these uses might require separate implementations of the same functionality.
Desktop and Web programmers often tend to minimize the amount of logic in the data layer and put all the pressure on the application. That is often wrong because more optimal and more natural solutions can be implemented in the database. The cause for the logic misplacement is often found in insufficient knowledge about the database concepts, rather than in some profound understanding which would imply that particular logic should be placed in the application. The solution to the problem is obviously in getting more acquainted with database technologies so that their full power can be used for the better of the application and its users.