Computed Columns remain to be an unused feature in SQL Server. But if efficiently used, they can give us good flexibility and speed over the traditional approach.
What is Computed Column?
Computed Columns are those columns whose values are not stored in the table. Instead they will be calculated dynamically. They have a formula that creates them that could be a Function, another Column Reference or a Constant Value.
In the figure below, we can see that ProjectName is a Computed Column. The Column Properties sets the column specification to a user defined method named GetProjectName() passing the ProjectId as argument.
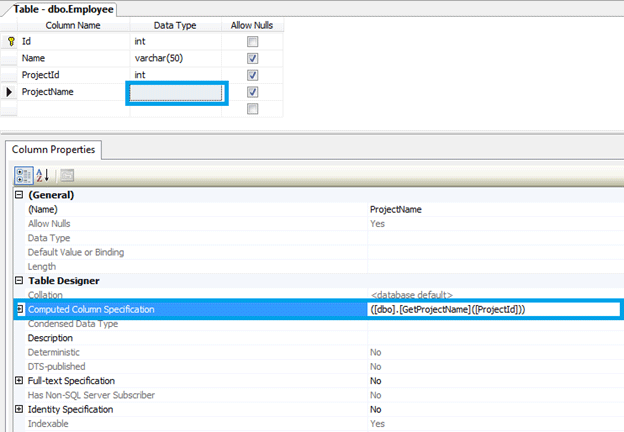
Let us see how we can benefit from it.
Example
We have two tables in this example - Employee and Project. The tables are related through the ProjectId column as shown below:
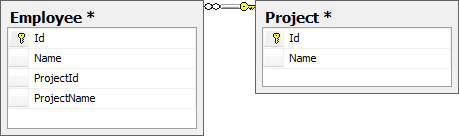
The Problem
We need to get the ProjectName of each Employee without using join statement as the join statement will create alterations in SQL statement.
The Solution
Here we can introduce the computed column ProjectName which in turns calls a user defined function to get the actual project name based on the ProjectId.
The following is the User Defined Function to do that:
CREATE FUNCTION [dbo].[GetProjectName]
(
@Id int
)
RETURNS varchar(50) AS
BEGIN
DECLARE @Result varchar(50)
SET @Result = (SELECT Name FROM Project WHERE Id=@Id)
RETURN @Result
END
Advantages
The following advantages can be identified from the above scenario:
- Less Overhead - While connecting with ORM tools we do not need to call specific methods to invoke the table or filter on the column.
- Speed Optimization on Filtering - As the calculation and filtering done on the server side only the required rows are passed over the wire. Otherwise without a computed column, the whole table will be fetched and processed thereafter filtering - this will increase the network traffic as well.
Testing It - Creating Data
After creating the necessary tables and functions, we can use the following insert SQLs to create the data. (the associated SQL files are attached with the article):
-- Create data in Project table
INSERT INTO [Project] ([Id], [Name]) VALUES (1, 'Project1');
INSERT INTO [Project] ([Id], [Name]) VALUES (2, 'Project2');
INSERT INTO [Project] ([Id], [Name]) VALUES (3, 'Project3');
GO
-- Create data in Employee table
INSERT INTO [Employee]([Id], [Name], [ProjectId]) VALUES (1, 'Employee1', 1);
INSERT INTO [Employee]([Id], [Name], [ProjectId]) VALUES (2, 'Employee2', 2);
INSERT INTO [Employee]([Id], [Name], [ProjectId]) VALUES (3, 'Employee3', 3);
INSERT INTO [Employee]([Id], [Name], [ProjectId]) VALUES (4, 'Employee4', 1);
INSERT INTO [Employee]([Id], [Name], [ProjectId]) VALUES (5, 'Employee5', 2);
Testing It - Selecting Data
SELECT * FROM Employee;
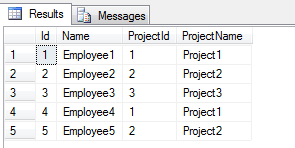
From the above result we can see that the ProjectName column is returning values appropriately.
About Project Attachment
The associated SQL files are attached with the project zip files. There are 2 SQL files. Please run them in the correct order.
Note
The example provided above is a simple scenario. In the real world, we can address more complex issues like looking up multiple tables to get the required column value. This could be done through the same User Defined Function and associated Computed Column.