SQL Index Statement
Introduction
In this chapter, we learned how to use a SQL Create Index statement with various options.
SQL Create Index Statement
The SQL Create statement is used to create indexes in tables. Indexes are used to retrieve data from indexes rather than otherwise. Users can not see indexes, they are only used to speed up searches/queries in SQL.
It creates an index on a table. Duplicate values are allowed. It creates a relational index on a table or view. It's also called a rowstore index because it is either a clustered or nonclustered B-tree index. You can create a rowstore index before there is data in the table. Use a rowstore index to improve query performance, especially when the queries select from specific columns or require values to be sorted in a particular order in database tables.
Note
SQL Data Warehouse and Parallel Data Warehouse currently do not support unique constraints. Any examples referencing unique constraints are only applicable to SQL Server and SQL Database.
Syntax
- CREATE INDEX index_name
- ON table_name (column1, column2, ...);
Create a simple nonclustered rowstore index
The following examples create a nonclustered index on the OrderId column of the OrderDetails table.
Syntax
- CREATE INDEX ProductId ON orderDetails (OrderId);
- CREATE INDEX ProductId ON OrderDetails (OrderId DESC, OrderName ASC, OrderAddress DESC);
- CREATE INDEX ProductId ON OrderDetails (OrderId);
Create a simple nonclustered rowstore composite index
The following example creates a nonclustered composite index on the OrderName and OrderAddress columns of the OrderDetails table.
Syntax
- CREATE NONCLUSTERED INDEX ProductId ON OrderDetails (OrderName, OrderAddress);
Create an index on a table in another database
The following example creates a clustered index on theOrderId column of the OrderDetails table in the sample database.
Syntax
- CREATE CLUSTERED INDEX ProductId ON OrderDetails (OrderId);
Add a column to an index
The following example creates index IX_FF with two columns from the OrderDetails table The next statement rebuilds the index with one more column and keeps the existing name.
Syntax
- CREATE INDEX ProductOrder ON OrderDetails (OrderName ASC, OrderAddress ASC);
- -- Rebuild and add the OrganizationKey
- CREATE INDEX ProductOrder ON dbo.OrderDetails (OrderName,OrderAddress, Orderdate DESC)
- WITH (DROP_EXISTING = ON);
Create a unique nonclustered index
Syntax
- CREATE UNIQUE INDEX ProductId ON OrderDtails(OrderId);
The following query tests the uniqueness constraint by attempting to insert a row with the same value as that in an existing row.
The following example creates a unique nonclustered index on theOrderName column of the orderDetails of the table in the sample database. The index will enforce uniqueness on the data inserted into the OrderName column.
Example
- SELECT OrderName FROM OrderDetails WHERE OrderName = 'Apple';
- GO
- INSERT INTO OrderDetails(OrderName, orderAddress,OrderDate)
- VALUES ('guava', 'NoidaSector150', GETDATE());
Example
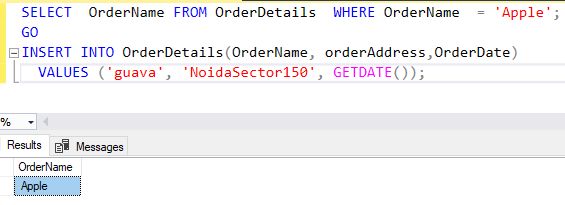
The above query is created to select the OrderName from OrderDetails Table and where clause for OrderName='Apple' and Insert the OrderName, OrderAddress, OrderDate.
How to use the IGNORE_DUP_KEY option?
The following example demonstrates the effect of the IGNORE_DUP_KEY option by inserting multiple rows into a temporary table first with the option set to On and again with the option set to Off. A single row is inserted into the ProductDetails table that will intentionally cause a duplicate value when the second multiple-row Insert statement is executed. A count of rows in the table returns the number of rows inserted.
Syntax
- CREATE TABLE ProductDetails (ProductId INT, ProductName NVARCHAR(10),ProductAddres NVARCHAR(50), ProductCity DATETIME);
- GO
- CREATE UNIQUE INDEX AK_Index ON ProductDetails(ProductAddres)
- WITH (IGNORE_DUP_KEY = ON);
- GO
- INSERT INTO ProductDetails VALUES (N'Mnago', N'Apple', GETDATE());
- INSERT INTO ProductDetails SELECT * FROM OrderDetails;
- GO
- SELECT COUNT(*) AS [Number of rows] FROM ProductDetails;
- GO
- DROP TABLE ProductDetails;
- GO
- The above query will create a table named ProductDetails
- Notice that the rows inserted from the ProductDetails table that did not violate the uniqueness constraint were successfully inserted. A warning was issued and the duplicate row ignored, but the entire transaction was not rolled back.
- The same statements are executed again, but with IGNORE_DUP_KEY set to OFF.
Using DROP_EXISTING to drop and re-create an index
The following example drops and re-creates an existing index on the OrderId column of the OrderDetails table in the sample database by using the DROP_EXISTING option. The options FILLFACTOR and PAD_INDEX are also set.
Syntax
- CREATE NONCLUSTERED INDEX OrderName
- ON OrderDetails (OrderId)
- WITH (FILLFACTOR = 80,
- PAD_INDEX = ON,
- DROP_EXISTING = ON);
- GO
How to create an index on a view statement?
The following example creates a view and an index on that view. Two queries are included that use the indexed view.
Syntax
- SET NUMERIC_ROUNDABORT OFF;
- SET ANSI_PADDING, ANSI_WARNINGS, CONCAT_NULL_YIELDS_NULL, ARITHABORT,
- QUOTED_IDENTIFIER, ANSI_NULLS ON;
- GO
- -- Create view with schemabinding
- IF OBJECT_ID ('Sales.vOrders', 'view') IS NOT NULL
- DROP VIEW Sales.vOrders;
- GO
- CREATE VIEW Product.vOrders
- WITH SCHEMABINDING
- AS
- SELECT SUM( * OrderQty * (1.00 - UnitPriceDiscount)) AS Revenue,
- OrderDate, ProductID, COUNT_BIG(*) AS COUNT
- FROM Sales.SalesOrderDetail AS od, SalesOrderHeader AS o
- WHERE od.SalesOrderID = o.SalesOrderID
- GROUP BY OrderDate, ProductID;
- GO
- -- Create an index on the view
- CREATE UNIQUE CLUSTERED INDEX IDX_V1
- ON Sales.vOrders (OrderDate, ProductID);
- GO
- -- This query can use the indexed view even though the view is
- -- not specified in the FROM clause.
- SELECT SUM(UnitPrice * OrderQty * (1.00 - UnitPriceDiscount)) AS Rev,
- OrderDate, ProductID
- FROM Sales.SalesOrderDetail AS od
- JOIN Sales.SalesOrderHeader AS o ON od.SalesOrderID = o.SalesOrderID
- AND ProductID BETWEEN 500 AND 600
- AND OrderDate >= CONVERT(DATETIME, '11/01/2020', 104)
- GROUP BY OrderDate, ProductID
- ORDER BY Rev DESC;
- GO
- -- This query can use the above indexed view
- SELECT OrderDate, SUM(UnitPrice * OrderQty * (1.00 - UnitPriceDiscount)) AS Rev
- FROM Sales.SalesOrderDetail AS od
- JOIN Sales.SalesOrderHeader AS o ON od.SalesOrderID = o.SalesOrderID
- AND DATEPART(mm, OrderDate) = 3
- AND DATEPART(yy, OrderDate) = 2020
- GROUP BY OrderDate
- ORDER BY OrderDate ASC;
- GO
- The above query creates an index with included (non-key) columns statement
- The following example creates a nonclustered index with one key column (OrderId) and three non-key columns (ordername, orderaddress, orderdate)
- A query that is covered by the index follows. To display selected optimizer, on the query menu in SQL server management studio, select "display" actual execution plan" before executing a query.
Syntax
- CREATE NONCLUSTERED INDEX New_OrderDetails
- ON OrderDetails (OrderId)
- INCLUDE (OrderName, OrderAddress, OrderDate);
- GO
- SELECT OrderName,orderAddress,OrderDate
- FROM OrderDetails
- WHERE OrderId BETWEEN 8 and 10;
- GO
Example
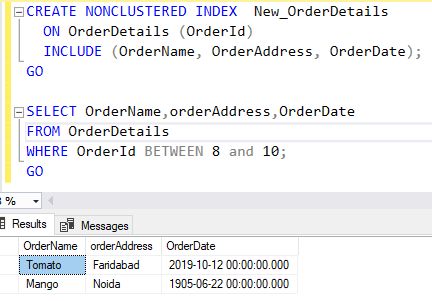
The above query will create NONCLUSTER INDEX ON OrderDetails table and add the OrderName, OrderAddress, OrderDate and select the columnName OrderName, orderAddress, OrderDate from OrderDetails Table and Where statement OrderId Between 8 To 10.
How to Create a partitioned index statement?
The following example creates a nonclustered partitioned index on Product_Details, an existing partition scheme in the sample database. This example assumes the partitioned index sample has been installed.
Syntax
- CREATE NONCLUSTERED INDEX Product_Details
- ON OrderDetails (OrderId)
- GO
How to create a filtered index statement?
The following example creates a filtered index on the OrderDetails table in the sample database. The filter predicate can include columns that are not key columns in the filtered index. The predicate in this example selects only the rows where EndDate is non-NULL.
Syntax
- CREATE NONCLUSTERED INDEX Product_List
- ON OrderDetails (OrderId, OrderName, OrderAddress)
- WHERE OrderDate IS NOT NULL;
How to create a compressed index statement?
The following example creates an index on a nonpartitioned table by using row compression.
Syntax
- CREATE NONCLUSTERED INDEX ProductDetails
- ON OrderDetails (OrderName)
- WITH (DATA_COMPRESSION = ROW);
- GO
The following example creates an index on a partitioned table by using row compression on all partitions of the index.
Syntax
- CREATE CLUSTERED INDEX Product_Details
- ON OrderDetails (OrderId)
- WITH (DATA_COMPRESSION = ROW);
- GO
The following example creates an index on a partitioned table by using page compression on partition 1 of the index and row compression on partitions 2 through 4 of the index.
Syntax
- CREATE CLUSTERED INDEX Product_Details
- ON OrderDetails (OrderId)
- WITH (
- DATA_COMPRESSION = PAGE ON PARTITIONS(1),
- DATA_COMPRESSION = ROW ON PARTITIONS (2 TO 4)
- );
- GO
Create, resume, pause, and abort resumable index operations
Syntax
- -- Execute a resumable online index create statement with MAXDOP=1
- CREATE INDEX OrderId ON OrderDetails (OrderId) WITH (ONLINE = ON, MAXDOP = 1, RESUMABLE = ON);
- -- Executing the same command again (see above) after an index operation was paused, resumes automatically the index create operation.
- -- Execute a resumable online index creates operation with MAX_DURATION set to 240 minutes. After the time expires, the resumable index creates operation is paused.
- CREATE INDEX OrderId ON EmployeeDetail (EmpName) WITH (ONLINE = ON, RESUMABLE = ON, MAX_DURATION = 240);
- -- Pause a running resumable online index creation
- ALTER INDEX EmpId ON employeDetail PAUSE;
- ALTER INDEX EmpName ON EmployeeDetail PAUSE;
- -- Resume a paused online index creation
- ALTER INDEX EmpId ON employeDetail RESUME;
- ALTER INDEX EmpName ON EmployeeDetail RESUME;
- -- Abort resumable index create an operation which is running or paused
- ALTER INDEX EmpId ON employeDetail ABORT;
- ALTER INDEX EmpName ON EmployeeDetail ABORT;
The above query will create Index OrderId from EmployeeDetail table name from EmpName with Online=on, Resumable= on, MAX_DURATION=240, And the ALTER INDEX to add column name EmpId, EmpName on EmployeeDetail Table name PAUSE, RESUME, ABORT statement.
How to create a nonclustered index on a table in the current database?
The following example creates a nonclustered index on the OrderId column of the OrderDetails table.
Syntax
- CREATE INDEX OrderName
- ON OrderDetails (OrderID);
How to create a clustered index on a table in another database?
The following example creates a nonclustered index on the OrderId column of the OrderDetails table.
Syntax
- CREATE INDEX NewOrderDetails
- ON OrderDetails(OrderId);
How to create a clustered index on a table in another database?
The following example creates a nonclustered index on the OrderName column of the OrderDetails table.
Syntax
- CREATE CLUSTERED INDEX Order_Id
- ON OrderDetail (OrerName);
Summary
In the next chapter, we will learn how to use a SQL UNIQUE statement with various options.
Author

Naresh Beniwal
Tech Writter
7.1k
1.8m