I am trying to make a program which extracts the text from a PDF document PDF documents contain ARABIC text written by different types of FONT
when I extract the text it works with some files and others not it gives me ambiguous Text
I am using c # and Itext7 to make this program
please show me the methodology to do this with some examples
thank you
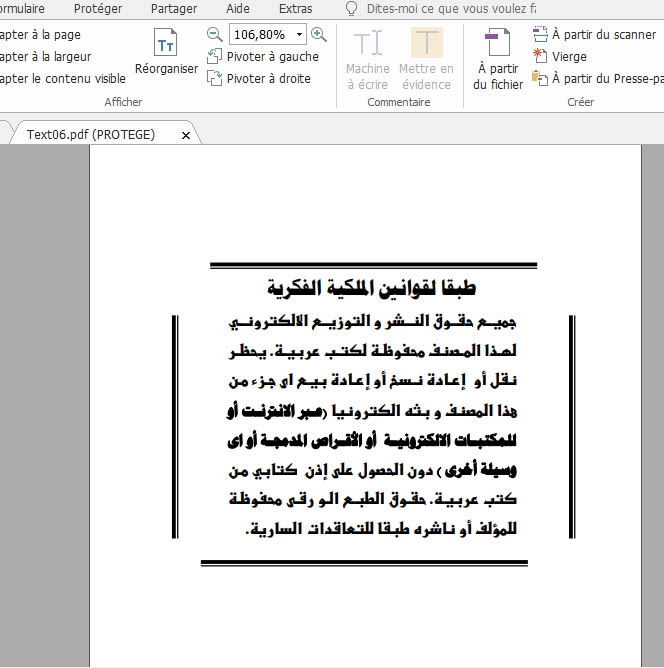

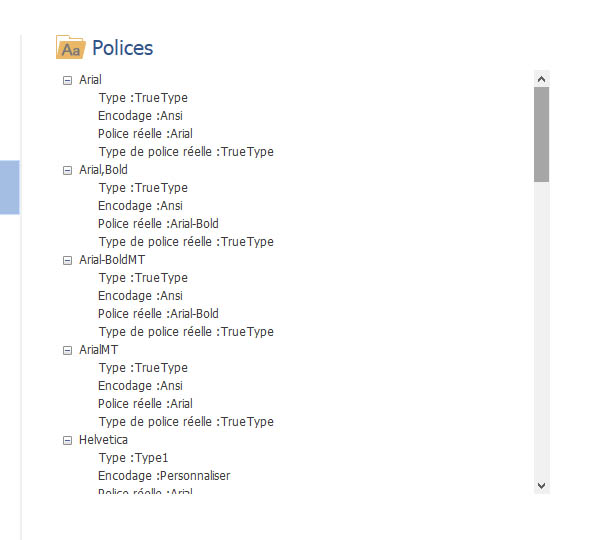
My code :
StringBuilder processed = new StringBuilder();
var src = "d:\\text06.pdf";
var pdfDocument = new PdfDocument(new PdfReader(src));
var strategy = new LocationTextExtractionStrategy();
for (int i = 1; i <= pdfDocument.GetNumberOfPages(); i++)
{
PdfPage page = pdfDocument.GetPage(i);
PdfDictionary fontResources = page.GetResources().GetResource(PdfName.Font);
//foreach (PdfObject font in fontResources.Values(true))
//{
// if (font is PdfDictionary)
// fontResources.Put(PdfName.Encoding, PdfName.IdentityH);
// }
string output = PdfTextExtractor.GetTextFromPage(page);
processed.Append(output);
}
string[] lines = Regex.Split(processed.ToString(), "\n");
List<String> Converted_Lines = new List<string>();
foreach (string s in lines)
{
string converted_string = Inverse(s);
Converted_Lines.Add(converted_string);
}
textBox1.Text = String.Join(Environment.NewLine, Converted_Lines);