Introduction
Azure Synapse SQL is a technology that resides inside the Synapse workspace. Azure synapse architecture is something we look into in this series of articles. In total, we have two pools discussed in detail in one of our articles a few weeks ago. Let's start with SQL pools.
- Dedicated SQL Pool
- Serverless SQL Pool
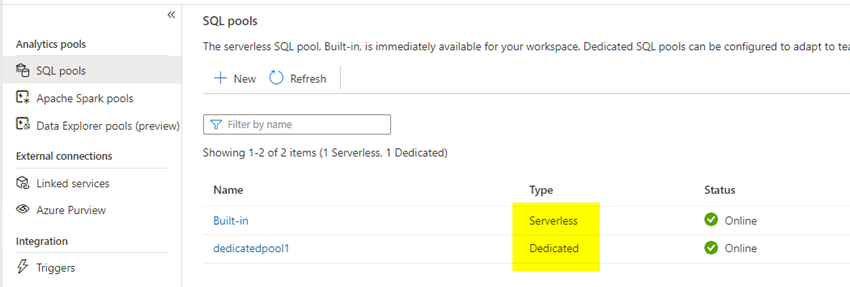
The built-in 'Serverless SQL Pool' gets created automatically when you create the workspace, and the user creates the 'Dedicated SQL Pool.' The 'Dedicated SQL Pool, ' formerly Azure DataWarehousing, creates a database in the backend that will be visible from the Data tab on the left side pane. So keep in mind that whenever you create a dedicated SQL pool, you also create a database in the backend.
![Architecture of Azure Synapse Analytics]()
The major difference between the two pools is cost-effectiveness. The serverless SQL pool works based on the 'Pay what you use' method, meaning you have to pay only for the resources you use when you run the query accessing data from ADLS gen2 or Blob storages. You incur no other charges. In the dedicated SQL pool, you will have dedicated resources created for you, like a database and the run-time engine. The computing power is defined as DWU(data warehousing units), and you must select it when creating the dedicated SQL pool. DWU is a computed power engine that runs the queries and processes the data, and the Database created by the dedicated SQL pool is the storage.
When you try to ingest data into a dedicated SQL pool database, the synapse architecture will store the data distributedly. The data will be partitioned into multiple distributions and then stored to optimize performance.
There are three types of sharding patterns available in synapse SQL.
- Hash
- Round Robin
- Replicate
You can specify which distribution pattern you need when creating a new table. I have scripted the query to show how the distribution parameter will look.
![Architecture of Azure Synapse Analytics]()
Synapse SQL utilizes node-based architecture. The 'Control Node' acts as a central system of the synapse SQL architecture. It is the entry point for all the requests and processes made to the synapse and is common for both Dedicated and Serverless SQL pool models.
![Architecture of Azure Synapse Analytics]()
The Dedicated SQL Pool follows true MPP (Massively Parallel Processing) architecture. It collects the submitted queries and transforms them into parallel queries, and each query is then passed on to compute nodes. Once the query executions are completed by all of the distributions /compute nodes, the data has to be collected to present a single result output. To perform this dedicated SQL pool deploys the DMS (Data Movement Service), which moves the data between the compute nodes and then presents a single output unit.
In Serverless SQL Pool, the queries will be divided into multiple tasks and assigned to many compute nodes, utilizing azure storage to process that data. Similar to DMS in the dedicated SQL pool, this is performed by an internal feature called DQP (Distributed Query Processing Engine) which breaks down the bigger queries into several small tasks.
Summary
I hope this brings a basic understanding of how Azure synapse analytics works behind the scenes. This will provide answers on how the synapse processes the data in an optimized and effective manner and yet so quickly. More topics to come; stay tuned!
Reference
- Microsoft official documentation